重い作業でも使用量が増えないClaude Codeの運用設計。スキル・フック・オーケストレーション・記憶の4層

結論から言うと、AIの成果は「どのツールを使うか」ではなく「どう組むか」で決まります。私は2名の会社で、Claude Code を業務の中枢に据えています。経理も、議事録も、メール返信も、このブログ記事の制作も、広告の出稿も、ここを通る。そして相当な負荷の作業を回しても、使用量(クレジット)はそれほど伸びません。理由は根性でも我慢でもなく、運用を設計してあるからです。
この記事は、2026年7月時点でハイデフが実際に使っている構成をそのまま開示します。スキル15個、コマンド6個、サブエージェント9体、ルール4本、外部連携(MCP)11本、自動フック4系統。地方の2名の会社でも、ここまで組めます。
差がつくのは「使い方」ではなく「運用設計」だ
生成AIを開いてプロンプトを打つ。ここまでは誰でもできます。差がつくのはその先、同じ品質を再現する仕組みを持っているかです。プロンプトの一発芸は、打った本人の調子とその日の気分に成果が左右される。仕組みは、そうならない。
私がこの1年で洗練させてきたのは、プロンプトの上手さではありません。Claude Code を「毎回ゼロから指示する相棒」から「会社のルールと過去の学びを積んだ実務OS」に変える、その設計です。具体的には次の4層で組んでいます。

4層で組む——ルール・スキル・オーケストレーション・記憶
4層それぞれに役割があります。単発の便利ツールではなく、積み上がる資産にするための構造です。
層 | 役割 | 実例 | 件数 |
|---|---|---|---|
ルール | 会社の判断基準を常に読ませる。品質ゲート | 文体・ブランドボイス・リサーチ品質・戦略品質 | 4本 |
スキル/コマンド | 頻出の作業手順を型にして呼び出す | 市場調査・競合分析・議事録・記事制作・広告出稿 | 15+6 |
オーケストレーション | 難易度で仕事を振り分け、並列で回す | 調査・分析・戦略・執筆の専門エージェント | 9体 |
記憶 | 過去の学びと失敗を蓄積し再利用する | lessons(学びログ)・memory(自己記憶) | 26件+ |
ポイントは、この4層が最初から在ったわけではないということです。訂正されるたび、手戻りが起きるたびに1枚ずつ足してきた。使い込むほど積み上がる設計にしてあるから、時間が経つほど楽になります。
設計思想は「最悪を織り込む」こと
ここで、根っこにある考え方を一つ明かします。私の運用設計は、一貫してネガティブな出発点から始まっています。AIは間違える。私は忘れる。事故は起きる。まず、そう置く。そのうえで、間違いと事故を機械的に止める仕組みを先に組んでおく。すると逆に、安心して速く動けるようになります。
「うまくいく前提」で組んだ仕組みは、想定外が起きた瞬間に止まります。「事故る前提」で組んだ仕組みは、止まらない。データベースへの直接書き込みを禁止するフックも、散らかりを自動で片付けるフックも、失敗を学びログに残す仕組みも、根っこは全部同じです。性悪説で仕組みを組み、性善説で動く。悲観を設計の中に閉じ込めてしまうから、日々の行動は楽観でいられる。
これは精神論ではありません。気合いで注意深くあろうとするのではなく、注意深さそのものを機械に肩代わりさせる。だから、疲れていても品質が落ちない。ネガティブを出発点に置くことは、後ろ向きではなく、前に進み続けるための土台なんです。
手戻りを消す仕掛け——品質ゲートと自動フック
結論から言うと、人間が毎回やっていた「確認」と「後片付け」を機械に落とすと、作業は静かに速くなります。ハイデフでは2つの仕掛けで、雑務をAIとの対話から外しています。
1つ目がルール=品質ゲートです。各ルールには「どのフォルダを触るときに効くか」を指定してあり、記事フォルダを触ればコンテンツ制作ルールが、リサーチ成果物を触れば品質基準が、自動で適用される。文体がブレたドラフト、ソースの無い数字は、その場で差し戻される仕組みです。
2つ目がフック。ユーザーの許可を待たずに走る自動処理で、いま4系統動いています。
- 停止時の自動検証:作業が一区切りするたび、直近で触ったコードを構文チェックし、データベースの整合性まで確認して報告する
- DBガード:会社の正本データベースへの直接書き込みを機械的に禁止する(事故防止)
- 散らかり自動掃除:フォルダのルート直下に紛れた一時ファイルを、自動で退避する
- 「おはよう」で朝の情報チェック起動:短く「おはよう」と打つだけで、カレンダー・メール・タスクの確認が自動で走る
どれも、以前は私が手でやっていたか、やり忘れて事故になっていた作業です。それを機械に任せた。雑務は対話から外す。人間は判断だけに集中する。これが手戻りを消す一番効く方法でした。
難しい仕事だけ、賢いモデルを使う
ここがコスト効率の肝です。すべての作業に最上位のモデルを使うのは、軽トラで買い物に行くのにダンプカーを出すようなもの。私はタスクの複雑度でモデルを使い分けています。
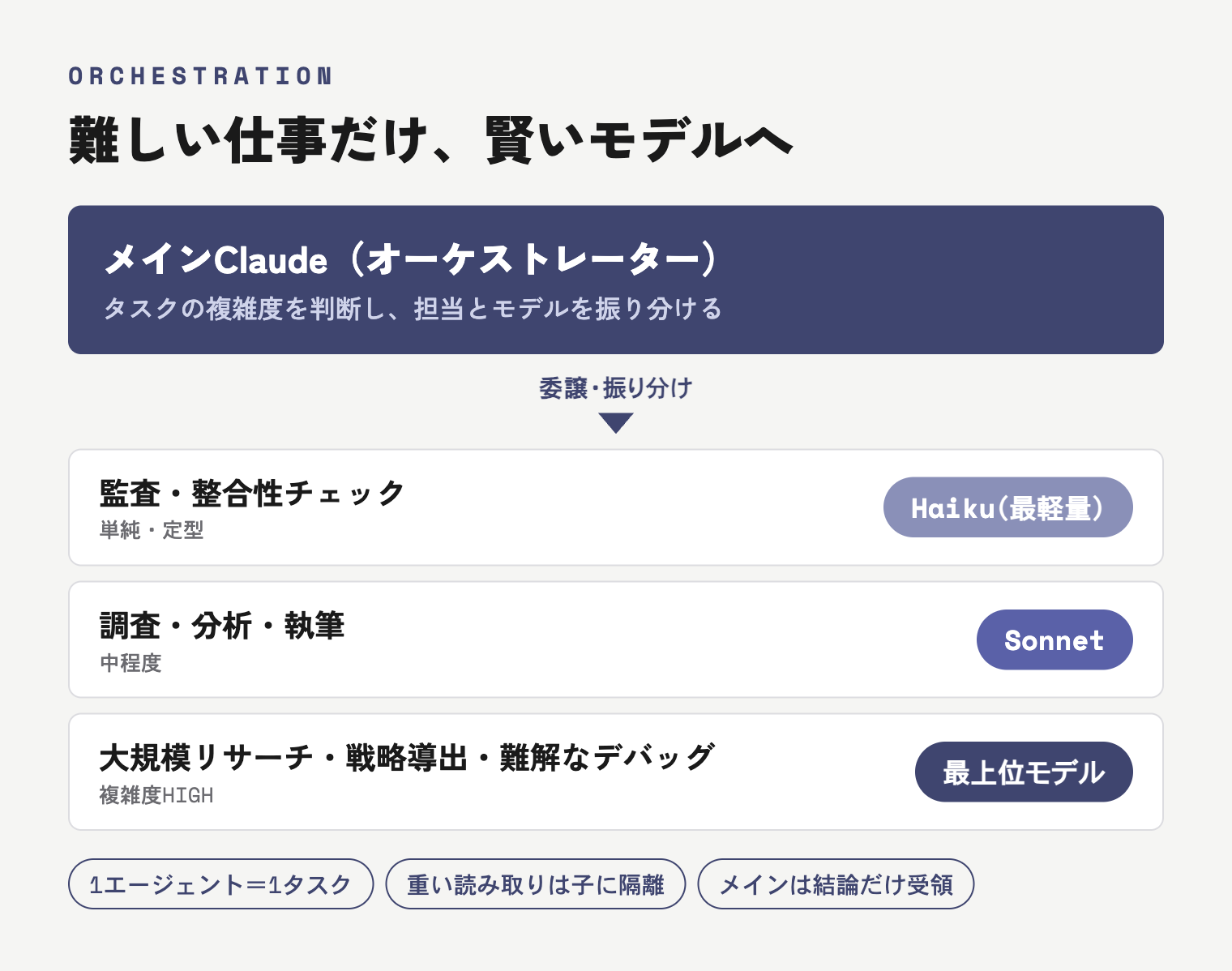
- 単純な監査・整合性チェック:最軽量のモデル(Haiku)に任せる
- 調査・分析・執筆:中位のモデル(Sonnet)で回す
- 大規模リサーチ・戦略導出・難解なデバッグ:ここだけ最上位モデルを起動する
もう一つ効くのがサブエージェントへの委譲です。大量のファイルを読む調査は、専門の子エージェントに丸ごと押し込む。メインの私(オーケストレーター)は、その結論だけを受け取る。重い読み取りでメインの作業領域を汚さない——これが効率と品質の両方を守ります。1つのエージェントには1つのタスクしか渡さない、というルールも徹底しています。
なぜ重い作業でも、使用量が跳ねないのか
結論から言うと、使用量はタスクの量ではなく、どれだけ無駄なトークンを捨てられるかで決まります。作業を増やしても、無駄を捨て続ければ消費は比例して増えない。ハイデフが使用量を抑えている仕掛けは、次の6つです。
仕掛け | 何を捨てているか |
|---|---|
コンテキスト衛生 | 使用率をバーで常時可視化し、節目で会話を圧縮・無関係な作業の前にはリセット。膨らんだ文脈を運び続けない |
サブエージェント隔離 | 重い調査の中身は子に閉じ込め、メインは結論だけ受け取る。探索の残骸を本体に持ち込まない |
モデルの使い分け | 軽い仕事に高いモデルを使わない |
自動フック | 検証・掃除・DBガードを機械に任せ、AIとの対話ターンを消費しない |
型化(スキル・ルール) | 毎回ゼロから手順や前提を説明しない |
記憶(学び・自己記憶) | 同じ調査・同じ失敗を二度繰り返さない |
言い換えると、私がやっているのは「たくさん使う工夫」ではなく「無駄を出さない工夫」です。膨らんだ会話を延々と引きずれば、1回のやり取りが重くなる。だから節目で捨てる。可視化バーが黄色になれば圧縮を検討し、赤になれば必ず圧縮する。無関係なタスクに移るときは会話ごとリセットする。この衛生習慣だけで、重い1日を回しても使用量は驚くほど伸びません。
実際の数字を出します。この記事そのものを作ったセッション——リサーチ用のサブエージェント起動、図解3枚のブラウザレンダリング、CMSへの入稿と検証まで含めて、実作業およそ2時間——の消費が、定額プランの週あたりの枠の6%でした。従量課金に換算しても$12.83。かなり重い部類の作業をひと回しして、この程度です。
理由の一つはキャッシュです。このセッションで読み込んだ入力のうち、約1,160万トークンはキャッシュからの再利用でした。会社のルールやファイルという同じ前提を毎回フルで課金し直すのではなく、使い回している。だから作業を積み重ねても、入力コストは素直には膨らみません。
そしてもう一つ。使用量はブラックボックスではありません。Claude Codeは内訳を見せてくれます。今日のセッションなら「消費の61%はサブエージェントの多用」「53%は15万トークンを超える長い文脈」と、どこが効いているかが数字で分かる。分かれば、削れる。使用量は勘で怯えるものではなく、計器を見て調整する変数です。ここでも思想は同じで、無駄が出る前提で計器を組んでおくから、安心してアクセルを踏めます。
「AIは使うと高い」のではありません。無駄に使うと高い。設計すれば、使った量ではなく、無駄の量で決まります。
失敗を資産に変える——自己改善ループ
この構成が効く最大の理由は、間違えるたびに賢くなることです。私が訂正すると、Claude はその原因を「学びログ」に記録し、再発を防ぐルールを自分で書きます。いま26件たまっています。実例を挙げます。
- あるツールがデバッグ設定時に環境変数を平文で出力し、機密が漏れかけた → 起動手順のルール化
- 画像のメタデータ除去ツールが、AI生成の来歴情報を見落としていた → 専用スキルを改修
- メールは作成しても送信前に必ず人が確認する → 例外なしのルールに
1回目の失敗は事故です。2回目の同じ失敗は設計ミスです。失敗を個人の反省で終わらせず、仕組みに変換する。これができると、同じ担当者が2人目、3人目に増えても品質が落ちません。属人化の逆を、AI運用で実装しているわけです。
地方の中小企業こそ、この設計が効く
正直に言うと、この運用に高度なプログラミングは要りません。要るのは「自社の判断基準を言語化する力」と「失敗を仕組みに変える規律」です。どちらも経営者の仕事の中身そのものではないでしょうか。
地方の中小企業は、意思決定者と現場の距離が近い。全社一斉ではなく、1つの業務から局地戦で始められる。大企業のような合意形成のコストがない分、設計して回し始めるまでが速い。ここは地方の弱みではなく、明確な強みです。2名の会社がここまで組めているのが、その証拠です。
FAQ
Q. エンジニアでないと使えないのでは?
いいえ。私は経営者で、コードを書くのが本業ではありません。それでも経理・議事録・メール・記事制作・広告出稿まで回しています。必要なのはプログラミング能力より、自社のルールを言葉にする力です。
Q. 重い作業を回すと料金が跳ね上がりませんか?
使用量はタスクの量ではなく設計で決まります。膨らんだ文脈を捨てる、軽い仕事に高いモデルを使わない、雑務は自動化する。この3つだけで、作業量のわりに消費は伸びにくくなります。
Q. 何から始めればいいですか?
まず「会社のルールを書いた1枚」と「よく使う作業を型にした1つのコマンド」から。最初から15個のスキルは要りません。型化を1つ作り、訂正のたびに1枚足す。それだけで積み上がります。
Q. 地方の小さな会社でも意味がありますか?
むしろ有利です。意思決定が速く、1部署から局地戦で始められる。全社導入で失敗する大企業より、成果を数字で証明してから横展開する道を取りやすい。
まとめ
AIの成果は、ツールの性能ではなく運用設計で決まります。ルール・スキル・オーケストレーション・記憶の4層で組み、雑務は機械に落とし、難しい仕事だけ賢いモデルに任せ、無駄なトークンを捨て続ける。そして失敗を仕組みに変える。根っこにあるのは、悲観を設計に閉じ込め、行動は楽観でいくという一貫した思想です。使い込むほど賢く、安くなる設計は、地方の2名の会社でも作れます。